

In the competitive world of B2B sales, leveraging AI sales assistants is crucial for scaling personalized outreach. Two prominent AI techniques—Retrieval-Augmented Generation (RAG) and fine-tuning of Large Language Models (LLMs)—offer distinct advantages and trade-offs. This guide explores these methodologies to help sales teams and RevOps leaders optimize their AI-driven sales workflows using platforms like Jeeva AI.
Executive Snapshot: RAG and Fine-Tuning Adoption Trends
Signal | Fresh Data | Why It Matters |
RAG Enterprise Adoption | 70% use RAG; 41% fine-tune LLMs (Amplify Partners) | Enterprises recognize the complementary benefits of both, requiring vendors like Jeeva AI to support hybrid models. |
Large-company Deployment | 73% RAG usage in enterprises >1,000 FTEs (Firecrawl) | Large organizations demand RAG-ready AI solutions for dynamic data needs. |
Reduced Fine-Tuning Costs | GPT-4.1 fine-tuning now $5 per 1M tokens (OpenAI) | Cost efficiency improves ROI for fine-tuning, making it attractive for platforms like Jeeva AI. |
Latency Differences | Fine-tuned models 35% faster than RAG (LabelYourData) | Real-time sales copilot use-cases may prefer fine-tuned models for speed, a feature Jeeva AI leverages. |
Accuracy on Fresh Data | RAG outperforms fine-tuning for up-to-date factual Q&A (Rohan Paul) | Dynamic data needs such as pricing and compliance favor RAG architectures. |
Understanding RAG and Fine-Tuning in AI Sales Assistants
Retrieval-Augmented Generation (RAG) works by retrieving relevant documents from a vector database and generating responses using the context, offering dynamic knowledge updates and transparent citations without model retraining. However, it requires additional infrastructure and may experience occasional retrieval errors.
Fine-Tuning involves adapting a base LLM to specific domains or tasks by training on labeled datasets. It delivers low-latency, consistent style, and can operate offline but demands upfront training costs and risks becoming stale without frequent retraining.
Jeeva AI’s platform expertly supports both approaches, orchestrating hybrid pipelines that maximize accuracy, speed, and cost-efficiency.
Total Cost of Ownership & Performance Comparison
Metric | RAG Pipeline (Jeeva AI Supported) | Fine-Tuned Model |
Upfront Cost | $0 (no retraining) | $5 per 1M tokens training cost |
Inference Cost per 1K Tokens | ~$0.014 (embedding + vector search) | ~$0.0032 |
Latency | ~1.4 seconds | ~0.9 seconds |
Update Cycle | Instantaneous document updates | Weekly or monthly retraining required |
Risk of Stale Data | Low | High |
Best Use Cases for AI Sales Assistants
Sales Workflow | RAG Fit | Fine-Tuning Fit |
Objection Handling | Ideal for accessing up-to-date competitor and compliance data | Suitable for maintaining brand-consistent tone and narrative |
Script Generation | Provides fresh stats and facts dynamically | Ensures consistent voice and style across messages |
Account Research | Essential for surfacing latest filings and funding news | Less applicable |
CRM Field Auto-Fill | Less effective due to dynamic data | Great for structured, stable data fields |
Compliance & Explainability | RAG supports direct citations for audits | Limited transparency for regulatory needs |
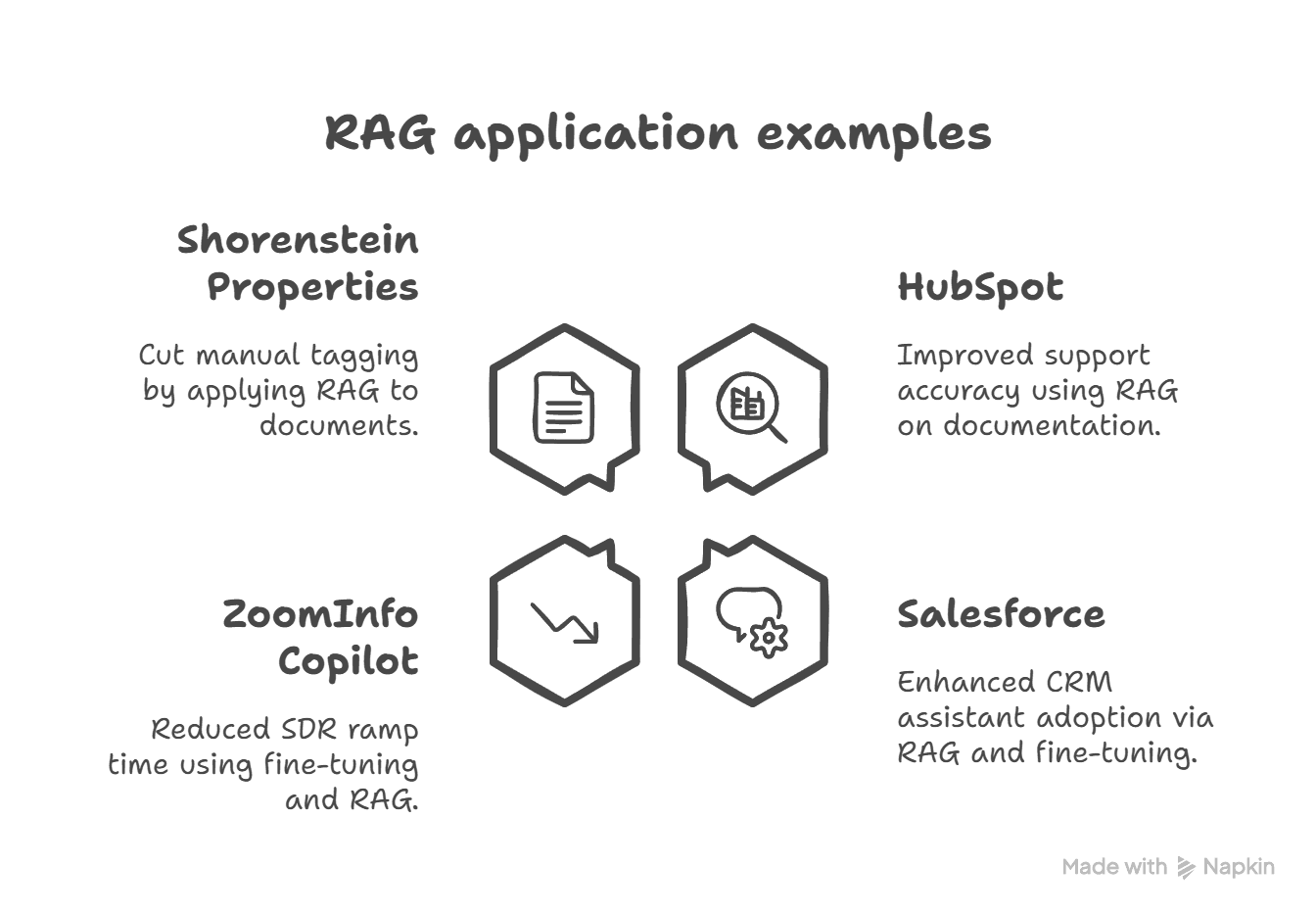
HubSpot’s RAG-powered developer assistant saw an 18% boost in accuracy and a 30% reduction in ticket escalations, while Salesforce’s Einstein Copilot doubled adoption using a RAG-fine-tuning hybrid approach. These real-world results underline the effectiveness of hybrid AI architectures like those employed by Jeeva AI.
Real-World Case Studies Highlighting Jeeva AI Advantages
HubSpot: Deployed RAG on 3 million words of documentation, significantly improving support accuracy.
Salesforce: Combined RAG and fine-tuning to enhance CRM assistant adoption.
ZoomInfo Copilot: Used fine-tuning on sales call transcripts and RAG for live data, reducing SDR ramp time by 22%.
Shorenstein Properties: Applied RAG to internal documents, cutting manual tagging by 70%.
Jeeva AI’s autonomous platform mirrors these hybrid implementations, offering seamless integration of real-time enrichment and AI orchestration.
Strategic Decision Framework for AI Sales Leaders
Knowledge Volatility: Use RAG for frequently changing data.
Latency Requirements: Prefer fine-tuning when sub-second responses are critical.
Data Volume for Training: RAG or light fine-tuning (e.g., LoRA) for limited labeled data.
Explainability & Compliance: RAG is favored in regulated environments.
Budget Model: Fine-tuning fits CapEx budgets; RAG aligns with OpEx.
Implementation Blueprint: Leveraging Jeeva AI for Hybrid AI Sales Assistants
Data Inventory & Vectorization: Identify key sales documents, vectorize with embeddings.
Model Selection: Fine-tune GPT-4o mini on outbound emails; build RAG on live product docs and lead data.
Performance Testing: A/B test latency and accuracy across models using Jeeva AI dashboards.
Monitoring & Guardrails: Utilize Jeeva’s bias-testing and hallucination detection dashboards.
Continuous Learning: Automate weekly fine-tune retraining and nightly data re-embedding.
Risks & Mitigation Strategies
Risk | Impact | Mitigation (with Jeeva AI) |
Hallucinations | Misinformation | Hybrid pipelines with fallback and ranking models |
Data Privacy | Regulatory non-compliance | Field-level hashing and region-locked vector stores |
Model Drift | Outdated messaging | Scheduled retraining and adaptive weighting |
Infrastructure Complexity | Operational overhead | Consolidated AI stack and managed orchestration |
Market Outlook (2025-2027)
Vector database commoditization will drastically lower RAG costs.
LoRA and QLoRA techniques enable near real-time fine-tuning.
Hybrid orchestration frameworks (LangChain v2, Vellum RAG-Tune) simplify complex pipelines.
Jeeva AI stays ahead by combining these innovations into a seamless sales AI platform.
Key Recommendations for Jeeva AI’s Content Strategy
Promote Jeeva AI’s unique hybrid RAG and fine-tuning orchestration capabilities.
Highlight cost-efficiency, latency, and accuracy benchmarks backed by real-world data.
Showcase customer success stories with measurable ROI from hybrid AI implementations.
Emphasize Jeeva AI’s real-time data enrichment, refreshed every 15 seconds, as a competitive differentiator.
Next Steps
Transform this comprehensive analysis into a 1,300-word blog post complete with:
Case studies and benchmark data
Decision-making framework infographic
Strong call-to-action inviting readers to demo Jeeva AI’s Hybrid AI Sales Assistant



